IFT2905 - Entrevues semi-structurées et Expériences Contrôlées
Mauvais guides d'entrevue
Avant d'entrer dans la théorie, lisez les deux guides d'entrevue suivants.
Question de recherche : « Comment les jeunes adultes gèrent-ils leur temps passé sur TikTok? »
Question de recherche : « Comment les gens intègrent-ils les assistants vocaux dans leur quotidien à la maison? »
Qu'est-ce qu'une entrevue semi-structurée?
Les entrevues semi-structurées font partie de la phase Comprendre du processus de design centré sur l'utilisateur.
Ce sont des méthodes qualitatives : elles ne testent pas des hypothèses préétablies, elles cherchent à comprendre comment les gens pensent, agissent et ressentent.
- On prépare un guide d'entrevue avec des questions planifiées
- Mais on n'est pas obligé de le suivre à la lettre on peut improviser selon ce que dit le participant
- Ce qui nous guide, c'est toujours la question de recherche et les objectifs
- Le guide peut être ajusté au fil des entrevues
Les entrevues qualitatives s'intéressent aux questions du type : « Qu'est-ce qui se passe? », « Comment les gens perçoivent X? », « Comment les gens utilisent X dans leur vie quotidienne? ».
La variation entre les participants n'est pas un problème c'est une source d'information.
Qui interviewer et où?
Qui interviewer?
Le choix des participants dépend de la question de recherche. On distingue plusieurs catégories :
| Type | Description | Mise en garde |
|---|---|---|
| Utilisateurs potentiels | Ceux qui utiliseront directement le produit | Priorité dans la plupart des études |
| Communauté touchée | Membres de la famille, collègues, aidants | Souvent des décideurs; perspectives sur contraintes et ressources |
| Experts du domaine | Connaissent bien l'espace problématique | Souvent des « power users » ne représentent pas les débutants |
Comment les recruter?
Médias sociaux, courriel, bouche-à-oreille (échantillonnage boule de neige), annonces en personne, dépliants. La méthode dépend de la population cible et du contexte de l'étude.
Entrevue vs entrevue contextuelle
Menée dans un espace neutre (bureau, café, Zoom). Facile à organiser. Peut être impersonnel l'environnement réel du participant est absent.
Menée dans l'environnement réel du participant. Permet de voir comment le contexte influence les comportements. Même pour des produits numériques, le cadre physique est révélateur.
Préparer le guide d'entrevue
Les quatre étapes
- Définir la question de recherche principale idéalement en une seule phrase
- Construire le guide autour de cet objectif
- Garder en tête la durée prioriser ce qui est essentiel si le temps manque
- Piloter le guide avant la première vraie entrevue
Structure du guide : introduction, approfondissement, conclusion
| Section | Objectif | Exemples de questions |
|---|---|---|
| Introduction | Mettre à l'aise, établir le contexte | « Qui êtes-vous? Que faites-vous dans la vie? » / « Utilisez-vous un portefeuille? » |
| Approfondissement | Explorer les expériences concrètes | « Quand avez-vous utilisé votre portefeuille pour la dernière fois? Racontez-moi ce moment. » / « Comment vous sentiez-vous? » |
| Conclusion | Questions larges, bilan, ce qu'on aurait oublié | « Qu'est-ce que vous aimez ou n'aimez pas de votre portefeuille? » / « Y a-t-il autre chose que vous aimeriez me dire? » |
Ce qu'on cherche à couvrir
- Objectifs du participant dans l'espace problématique qu'est-ce qui les motive?
- Comportements quoi, quand, où, pourquoi et comment ils atteignent leurs objectifs
- Défis et frustrations et les solutions de contournement qu'ils ont trouvées
- « Pouvez-vous me montrer? » toujours une bonne idée
Types de questions
Un bon guide d'entrevue mobilise différents types de questions selon ce qu'on cherche à comprendre :
| Type | Objectif | Exemple |
|---|---|---|
| Démographique | Antécédents et identité | « Quel est votre parcours professionnel? » |
| Définitionnelle | Comment le participant comprend une catégorie | « Pour vous, qu'est-ce qu'une bonne expérience numérique? » |
| Comportementale | Explorer les actions et expériences passées | « Décrivez-moi la dernière fois que vous avez utilisé cette application. » |
| Aspirationnelle | Espoirs et désirs pour le futur | « Dans un monde idéal, comment fonctionnerait cet outil? » |
| Explicative | Pourquoi les participants font quelque chose | « Pourquoi avez-vous choisi cette méthode plutôt qu'une autre? » |
| Émotionnelle | Explorer les sentiments et états affectifs | « Comment vous sentiez-vous pendant que vous utilisiez cet objet? » |
| Contextuelle | Le contexte et son influence sur le comportement | « Dans quel endroit utilisez-vous habituellement cette application? » |
| Sociale | Interactions avec les autres | « Est-ce que vous utilisez cette fonctionnalité avec d'autres personnes? » |
| Méta-perceptive | Comment on pense être perçu par les autres | « Comment pensez-vous que les autres vous perçoivent quand vous faites X? » |
L'importance de la mémoire
Pour obtenir des données riches, il faut se concentrer sur des expériences concrètes passées, pas des généralités.
Les formulations comme « rappelle-toi une fois où... » ou « parle-moi d'un moment précis où... » ancrent la conversation dans le réel.
Une stratégie alternative est l'évocation par la photo : demander au participant d'apporter des photos liées au sujet pour servir de point de départ.
À faire et à éviter
Les quatre types de questions biaisées
Questions auxquelles on peut répondre par oui/non, par une échelle, ou en un ou deux mots. Elles bloquent l'exploration.
« Est-ce que vous utilisez souvent TikTok? »
« Parle-moi d'une journée typique où tu as utilisé TikTok. »
Elles orientent l'esprit du participant vers une réponse particulière souvent celle qu'on espère entendre.
« Vous lui faites confiance, non? » / « Pourquoi avez-vous aimé notre interface? »
« Comment décririez-vous votre rapport à cet assistant vocal? »
Les questions générales produisent des réponses générales et souvent des réponses idéalisées plutôt que réelles.
« Quand utilisez-vous votre carte de crédit? »
« Quand avez-vous utilisé votre carte de crédit pour la dernière fois? Racontez-moi ce moment. »
Une seule question qui pose en réalité deux (ou plusieurs) questions différentes. Le participant ne sait pas à quoi répondre.
« Est-ce que votre famille utilise l'assistant vocal et comment ça change la dynamique familiale et la vie privée? »
Une question à la fois, avec des questions de suivi.
En résumé
- Questions ouvertes
- Une question à la fois
- Rappel d'une expérience concrète
- Visites guidées (« Raconte-moi comment tu fais X »)
- Questions de suivi (« pourquoi? », « comment? », « peux-tu me montrer? »)
- Questions fermées (oui/non)
- Questions suggestives
- Questions vagues ou générales
- Questions à double canon
- Questions sensibles sans rapport établi au préalable
Éthique et bonne conduite
Avant l'entrevue
- Bien connaître le sujet et le groupe recruté
- Définir clairement les objectifs et ce qu'on peut laisser de côté si le temps manque
- Préparer le formulaire de consentement, l'outil d'enregistrement, le carnet de notes
- Toujours piloter le guide pratiquer avec un proche avant la première vraie entrevue
- Prévoir deux personnes si possible : un intervieweur et un preneur de notes
Pendant l'entrevue
- Faire en sorte que ça ressemble à une conversation, pas à un interrogatoire
- Obtenir le consentement éclairé et demander la permission d'enregistrer
- Permettre au participant de passer des questions ou de se retirer à tout moment
- Respecter le temps prévu ne pas dépasser
- Éviter les stéréotypes à propos des participants
Éthique et sujets sensibles
De Retour!
Annoter les guides catastrophiques
Maintenant que vous avez les concepts, revenez aux deux guides du début. Pour chaque question, identifiez quel(s) type(s) de biais elle illustre, et proposez une version corrigée.
Annoter et corriger
Pour chaque question des deux guides, identifiez :
- Le type de biais (réponse courte, suggestive, générale, double canon)
- Pourquoi c'est problématique dans ce contexte précis
- Une version corrigée
Y a-t-il des questions qui posent aussi des problèmes éthiques? Comment les réécrire?
Plan d'expérience
Ce qu'on peut évaluer
Choisissez un scénario
IA médicale en milieu rural
Un système d'IA détecte les cataractes à partir de scans rétiniens dans des cliniques rurales en Thaïlande. Comment étudier l'impact du système sur les interactions médecin-patient et la précision du diagnostic?
Outil de visualisation de code
Une nouvelle technique de mise en évidence du code Rust révèle des informations sur le flux de propriété. Vous affirmez qu'elle améliore la productivité des programmeurs. Comment l'étudier?
Les « cozy games »
Vous voulez comprendre l'attrait des jeux vidéo « cozy » : pourquoi les gens les développent, pourquoi les gens y jouent, et s'il existe des différences entre leur façon d'y jouer et d'autres types de jeux.
Quel scénario avez-vous choisi?
Quelle(s) est/sont la/les question(s) de recherche ou hypothèse(s) auxquelles vous souhaitez répondre?
Qui allez-vous recruter pour l'étude? D'où? Quelle est la compensation, le cas échéant? (Si aucune compensation, pourquoi?)
Quelle(s) méthode(s) choisiriez-vous et pourquoi? Justifiez votre choix de méthodes.
Quelle est la structure générale de l'étude? Y aura-t-il des conditions et/ou des groupes? Quelles sont les variables indépendantes et dépendantes, le cas échéant?
Que feront les participant·e·s dans votre étude? Listez ce que vous leur demanderez de faire et combien de temps cela prendra. S'il y a plusieurs étapes, indiquez le temps pour chacune. Soyez précis·e·s.
Comment comptez-vous analyser les données recueillies? Décrivez votre approche d'analyse.
Comment allez-vous contrôler les variables/facteurs qui ne sont pas directement liés à l'étude, mais qui pourraient en affecter les résultats?
Comment allez-vous vous assurer que l'étude est éthique et ne présente qu'un risque minimal pour les participant·e·s?
Quelles sont les menaces à la validité de votre étude, le cas échéant?
Méthodes empiriques
Quantitatif vs qualitatif
Les méthodes empiriques en IHM se divisent en deux grandes familles.
Pas une hiérarchie! Les deux sont essentielles, et elles se complètent.
- Collecte de données en langage naturel
- Riches et complexes excellent pour saisir la variabilité et les aspects sociaux et culturels
- Méthodes : entrevues, observations, études ethnographiques, journaux, études de cas
- Analyse par codage qualitatif généralement inductif (de bas en haut)
- La variation t'inspire
- Collecte de données numériques analysées avec des statistiques
- Expériences, sondages, vérification d'hypothèses, analyse statistique
- Au moins deux « conditions » variées délibérément
- Tente de contrôler ou tenir compte de la variabilité non désirée
- La variation nuit (quand elle n'est pas contrôlée)
| Question de recherche | Méthode suggérée |
|---|---|
| « Qu'est-ce qui se passe? » | Qualitative |
| « Comment les gens perçoivent X? » | Qualitative |
| « Si les utilisateurs font X, est-ce que Y va se produire? » | Quantitative |
| « À quel point X influence-t-il Y? » | Quantitative |
| « Est-ce que X cause Y? » | Quantitative (expérience) |
Qualitatif ou quantitatif?
Pour chaque situation ci-dessous, déterminez si une méthode qualitative ou quantitative est la plus appropriée. Justifiez votre choix et décrivez quel type de données vous recueilleriez.
- Quels irritants les scientifiques des données rencontrent-ils lorsqu'ils utilisent les notebooks Jupyter?
- Comment les auteurs de fiction utilisent-ils des représentations non textuelles (diagrammes, croquis) lorsqu'ils planifient leurs histoires?
- Les développeurs de jeux sont-ils plus efficaces et plus satisfaits lorsqu'ils créent un jeu 2D avec Godot, comparativement à Unity?
- Comment la confiance des développeurs envers un assistant de programmation IA évolue-t-elle au fil du temps?
- En moyenne, y a-t-il des différences quant à l'endroit où les étudiant·e·s s'identifiant comme hommes ont tendance à étudier, comparativement à celles et ceux s'identifiant comme femmes?
Conception expérimentale
Les bases de la conception expérimentale
Qu'est-ce qu'une étude expérimentale?
Une étude expérimentale comporte au moins une variable que le chercheur fait varier délibérément afin de tester une hypothèse de recherche. On distingue :
| Terme | Définition | Exemple streaming |
|---|---|---|
| Variable indépendante (VI) | La variable que le chercheur fait varier délibérément | Type de contenu : Just Chatting vs Jeux vidéo |
| Condition / niveau | Les valeurs que prend la VI | 2 conditions : {Just Chatting, Gaming} |
| Variable dépendante (VD) | Ce qu'on mesure supposément influencé par la VI | Nombre de nouveaux abonnés; achalandage moyen |
| Variable confondante | Variable qui change sans qu'on la contrôle, corrélée avec la VI | Jour de la semaine, heure de diffusion, jeu choisi |
| Sujet / participant | L'unité d'observation dans l'étude | Chaque diffusion (ou chaque participant) |
Qu'est-ce qu'une hypothèse de recherche?
Une hypothèse de recherche est une formulation précise d'un problème qui peut être directement testée par une investigation empirique
Une bonne hypothèse est :
- Précise pas vague ou générale
- Testable on peut concevoir une étude pour la vérifier
- Intéressante non évidente, apporte quelque chose de nouveau
Hypothèse de départ : « Faire pousser des tomates dans mon jardin extérieur les fait pousser plus vite que dans un pot à l'intérieur de ma maison. »
| Composante | Dans cet exemple |
|---|---|
| Sujet | Plant de tomate |
| Variable indépendante | Emplacement 2 conditions : {jardin, pot intérieur} |
| Variable dépendante | Taux de croissance (valeur continue) |
| Variables confondantes possibles | Quantité d'eau, exposition au soleil, type de terre, température |
Hypothèse affinée : « Faire pousser des tomates dans la terre du jardin les fait pousser plus vite que dans un pot dans le jardin à l'intérieur de ma maison. » plus précise, contrôle le type de contenant.
Contrôler les variables confondantes
« Contrôler pour X » signifie prendre des mesures pour s'assurer que la variable X n'explique pas à elle seule les différences qu'on observe entre les conditions.
Si on ne contrôle pas X, on ne peut pas savoir si c'est la variable indépendante ou X qui produit l'effet mesuré.
Imaginons qu'on compare Godot et Unity sur la productivité des développeurs.
Si tous les participants du groupe Godot ont plus d'expérience en programmation que ceux du groupe Unity, on ne peut pas savoir si Godot est meilleur ou si c'est simplement parce que les participants plus expérimentés s'en sortent mieux peu importe l'outil.
L'expérience préalable est une variable confondante.
| Stratégie | Ce qu'on fait | Ce que ça élimine |
|---|---|---|
| Fixer la variable | On exige que tous les participants aient le même niveau d'expérience (ex. débutants seulement) | La variable confondante ne peut plus varier, donc elle ne peut plus expliquer les différences |
| Assignation aléatoire | On assigne les participants aux groupes au hasard | En moyenne, les groupes auront des niveaux d'expérience similaires si l'échantillon est assez grand |
| Mesurer et ajuster | On mesure la variable confondante et on en tient compte dans l'analyse statistique (ex. ANCOVA) | On essaie de retirer mathématiquement son effet des résultats |
On ne peut jamais contrôler toutes les variables confondantes possibles. L'objectif est d'identifier et de contrôler celles qui sont les plus susceptibles de biaiser les résultats.
Il existe trois stratégies principales :
- Fixer la variable maintenir sa valeur constante pour toutes les conditions (ex. toujours diffuser à 20h, toujours jouer à Minecraft)
- Assignation aléatoire répartir aléatoirement les sujets ou les conditions afin que la variation de la variable confondante soit distribuée également
- Blocage créer des « blocs » afin que chaque condition se produise un nombre égal de fois à l'intérieur d'un même bloc (ex. 3 diffusions gaming le soir, 3 Just Chatting le soir)
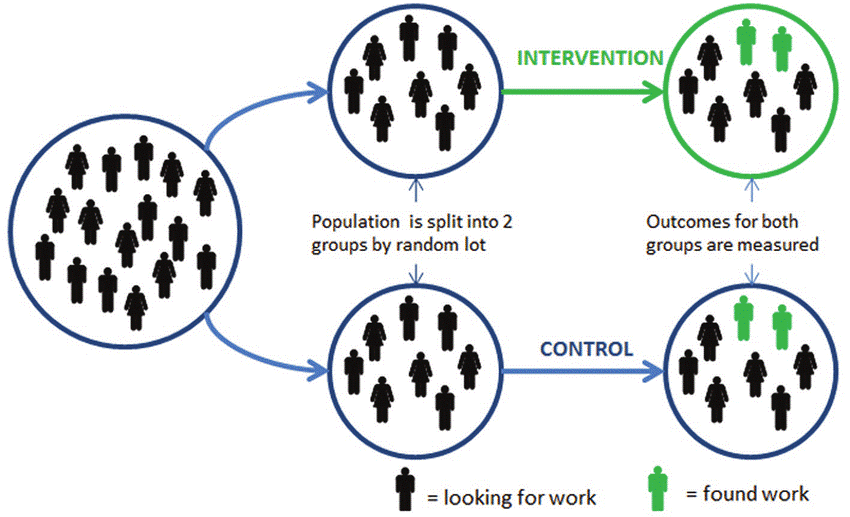
L'essai contrôlé randomisé (ECR)
L'assignation aléatoire est au cœur de ce qu'on appelle un essai contrôlé randomisé (ECR, ou RCT en anglais Randomized Controlled Trial).
C'est considéré comme le gold standard de la conception expérimentale pour établir des relations causales, particulièrement en médecine et en sciences sociales.
| Composante | Rôle | Exemple médicament vs placebo |
|---|---|---|
| Groupe expérimental | Reçoit l'intervention testée | Prend le médicament A |
| Groupe contrôle | Reçoit un placebo ou le traitement standard | Prend un placebo identique en apparence |
| Assignation aléatoire | Distribue les variables confondantes également entre les groupes | Tirage au sort pour décider qui reçoit quoi |
| Double-aveugle | Ni le participant ni le chercheur ne savent qui est dans quel groupe | Élimine les biais de l'observateur et du participant |
En IHM, les ECR stricts sont moins fréquents qu'en médecine il est souvent difficile d'aveugler les participants à la condition qu'ils expérimentent (on sait qu'on utilise Godot et non Unity).
Mais le principe de l'assignation aléatoire reste fondamental : sans elle, on ne peut pas éliminer l'hypothèse que des différences préexistantes entre les groupes expliquent les résultats observés.
Identifier et contrôler les variables
Pour chaque hypothèse ci-dessous, identifiez le ou les sujets, la ou les variables indépendantes, la ou les variables dépendantes, et les variables de confusion potentielles. Pour chaque variable de confusion, décrivez comment vous pourriez la contrôler. Note : ces hypothèses sont toutes trop vagues précisez-les aussi.
- Le médicament A aide les enfants à se rétablir de la grippe plus rapidement et de façon plus fiable que le médicament B.
- L'utilisation de TikTok cause le TDAH chez les adolescent·e·s.
Plans expérimentaux
Inter-sujets vs intra-sujets
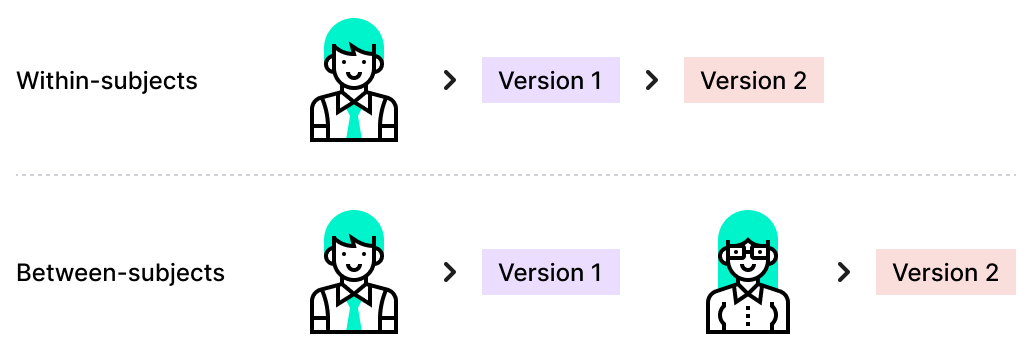
- Les participants sont répartis en groupes chaque groupe vit une seule condition
- Contrôle les effets d'ordre
- Souffre de la variation individuelle entre groupes
- Requiert plus de participants, mais moins de temps par participant
- Tous les participants expérimentent toutes les conditions
- Contrôle la variation individuelle
- Souffre des effets d'ordre (carryover effects)
- Requiert moins de participants, mais plus de temps par participant
- Risque d'effet Hawthorne plus élevé
Exemples concrets
Hypothèse : « Les développeurs de jeux sont plus efficaces et plus satisfaits avec Godot qu'avec Unity pour créer un jeu de plateforme 2D. »
| Participant | Condition | Mesures |
|---|---|---|
| P1, P2, P3... (groupe A) | Godot uniquement | Temps de complétion, satisfaction |
| P4, P5, P6... (groupe B) | Unity uniquement | Temps de complétion, satisfaction |
Pourquoi inter-sujets? Apprendre Godot influence directement l'expérience d'Unity et vice versa les effets de report seraient majeurs. Chaque participant ne voit qu'un seul moteur.
Hypothèse : « Écouter du bruit brun améliore la concentration lors de tâches d'écriture, comparativement à la musique préférée ou au silence. »
| Participant | Session 1 | Session 2 | Session 3 |
|---|---|---|---|
| P1 | Bruit brun | Musique | Silence |
| P2 | Musique | Silence | Bruit brun |
| P3 | Silence | Bruit brun | Musique |
| P4 | Bruit brun | Silence | Musique |
| P5 | Musique | Bruit brun | Silence |
| P6 | Silence | Musique | Bruit brun |
Pourquoi intra-sujets? Les différences individuelles de concentration sont énormes en faisant vivre les 3 conditions à chaque participant, on élimine cette source de variation. L'ordre est contrebalancé (carré latin 3x3 complet 3! = 6 ordres uniques, 6 participants minimum).
Hypothèse : « Les débutants apprennent plus vite avec Python qu'avec Java, mais l'effet est moins prononcé chez les étudiants avec de l'expérience préalable. »
| Python (condition A) | Java (condition B) | |
|---|---|---|
| Débutants complets | Groupe 1 | Groupe 2 |
| Avec expérience préalable | Groupe 3 | Groupe 4 |
Un plan 2x2 inter-sujets : deux variables indépendantes (langage et niveau d'expérience), chacune avec deux niveaux. Permet d'étudier les effets d'interaction l'effet du langage dépend-il du niveau d'expérience? C'est une question qu'on ne peut pas poser avec une seule VI.
Inter- ou intra-sujets?
Pour chaque hypothèse ci-dessous, choisissez un plan inter-sujets ou intra-sujets. Justifiez votre choix en fonction des variables et des menaces potentielles à la validité.
- Une nouvelle technique de visualisation au niveau des mots améliorera la vitesse de lecture et la compréhension, comparativement à l'absence de visualisation.
- Les étudiants débutants apprendront la programmation plus rapidement et avec moins de frustration si leur premier langage est Python, comparativement à Java.
- Une application qui motive les gens à faire de l'exercice cardio régulièrement augmente les niveaux de bonheur autodéclarés, comparativement à ne pas utiliser l'application.
- Écouter du bruit brun améliore la concentration lors de tâches d'écriture, comparativement à écouter sa musique préférée ou à n'écouter aucune musique.
- Les enfants ayant grandi dans des foyers où les parents limitaient fortement l'utilisation de la technologie connaissent un plus grand succès financier à l'âge adulte que ceux dont les parents imposaient peu ou pas de restrictions.
Plans intra-sujets
Effets de report et contrebalancement
Dans un plan intra-sujets, l'ordre dans lequel les participants expérimentent les conditions peut lui-même influencer les résultats.
C'est ce qu'on appelle un effet de report (carryover effect) ou effet d'ordre.
Combien d'ordres uniques?
Pour N conditions, le nombre d'ordres uniques possibles est N! (N factoriel) :
| N conditions | Calcul | Ordres uniques | Participants minimum |
|---|---|---|---|
| 2 | 2 × 1 | 2 | 2 |
| 3 | 3 × 2 × 1 | 6 | 6 |
| 4 | 4 × 3 × 2 × 1 | 24 | 24 |
| 5 | 5 × 4 × 3 × 2 × 1 | 120 | 120 impraticable! |
Pour un contrebalancement complet, chaque ordre unique doit être représenté par au moins un participant. Dès 5 conditions, c'est impraticable d'où le recours au carré latin.
Solution : le carré latin
Un carré latin organise N conditions sur N participants de façon à ce que chaque condition apparaisse exactement une fois par position et une fois par participant.
On contrebalance ainsi sur deux dimensions avec seulement N participants au lieu de N!.
| Participant | Position 1 | Position 2 | Position 3 |
|---|---|---|---|
| P1 | A | B | C |
| P2 | B | C | A |
| P3 | C | A | B |
Chaque condition (A, B, C) apparaît exactement une fois dans chaque colonne (position) et une fois dans chaque rangée (participant).
| Participant | Pos. 1 | Pos. 2 | Pos. 3 | Pos. 4 | Pos. 5 |
|---|---|---|---|---|---|
| P1 | A | B | C | D | E |
| P2 | B | C | D | E | A |
| P3 | C | D | E | A | B |
| P4 | D | E | A | B | C |
| P5 | E | A | B | C | D |
Problème : E apparaît après D dans 4 rangées sur 5. Si D est frustrante, E hérite de cette frustration c'est un effet de report non équilibré.
Le carré latin équilibré
Dans un carré latin équilibré, chaque condition précède et suit chaque autre condition un nombre égal de fois.
Pour un nombre pair de conditions, N rangées suffisent. Pour un nombre impair, il faut doubler 2N rangées, donc 2N participants minimum.
| N conditions | Carré latin standard | Carré latin équilibré |
|---|---|---|
| 2 (pair) | 2 participants | 2 participants |
| 3 (impair) | 3 participants | 6 participants (2 × 3) |
| 4 (pair) | 4 participants | 4 participants |
| 5 (impair) | 5 participants | 10 participants (2 × 5) |
| 6 (pair) | 6 participants | 6 participants |
| Participant | Pos. 1 | Pos. 2 | Pos. 3 | Pos. 4 | Pos. 5 |
|---|---|---|---|---|---|
| P1 | A | B | E | C | D |
| P2 | E | D | A | C | B |
| P3 | C | D | B | E | A |
| P4 | B | A | C | E | D |
| P5 | E | A | D | B | C |
| P6 | D | C | E | B | A |
| P7 | B | C | A | D | E |
| P8 | A | E | B | D | C |
| P9 | D | E | C | A | B |
| P10 | C | B | D | A | E |
Chaque condition suit et précède chaque autre condition exactement 2 fois sur les 10 rangées. Les effets de report sont ainsi équilibrés entre toutes les paires de conditions.
Le carré latin dans une conception expérimentale sur le streaming
Le carré latin ne sert pas uniquement au contrebalancement intra-sujets.
On peut l'appliquer à des études où on veut équilibrer deux dimensions qui ne sont pas des participants par exemple, des jours de la semaine et des semaines du calendrier :
| Semaine | Mardi | Mercredi | Jeudi | Vendredi |
|---|---|---|---|---|
| Semaine 1 | Just Chatting | Gaming | IRL | Art |
| Semaine 2 | Gaming | IRL | Art | Just Chatting |
| Semaine 3 | IRL | Art | Just Chatting | Gaming |
| Semaine 4 | Art | Just Chatting | Gaming | IRL |
Chaque type de contenu apparaît exactement une fois par jour de la semaine et une fois par semaine. Ni les jours ni les semaines ne biaisent les résultats d'une condition en particulier.
Contrebalancer une étude intra-sujets avec deux facteurs
Vous avez 4 conditions et 4 tâches, et vous pouvez recruter un maximum de 30 participants.
Concevez une procédure de contrebalancement intra-sujets pour assigner les participants aux conditions et aux tâches.
Créez un tableau avec les ID des participants et l'attribution des conditions et tâches en vous assurant qu'un nombre égal de participants expérimente chaque condition et chaque tâche à chaque position.
Quelle approche avez-vous utilisée et pourquoi? De combien de participants avez-vous besoin?
Difficile : Combien de participants vous faudrait-il pour un contrebalancement complet?
Taille d'échantillon
Analyse de puissance
Pour déterminer combien de participants recruter, on effectue une analyse de puissance avant l'étude. Quatre éléments sont nécessaires :
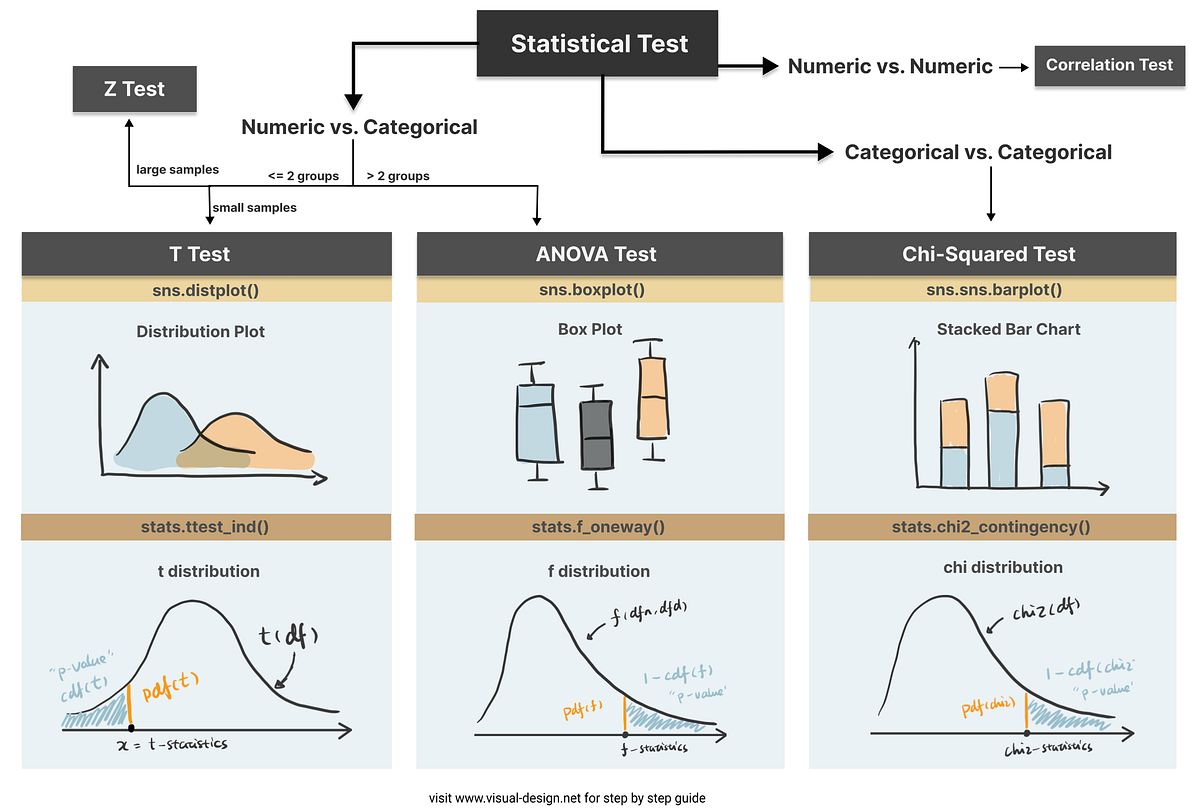
1. Le test statistique
Le choix du test dépend de la structure de l'étude :
| Situation | Test courant |
|---|---|
| 2 groupes indépendants (inter-sujets), 1 VD continue | t-test indépendant |
| 2 conditions, mêmes participants (intra-sujets), 1 VD continue | t-test apparié |
| 3 conditions ou plus, inter-sujets | ANOVA à un facteur |
| 3 conditions ou plus, intra-sujets | ANOVA à mesures répétées |
| 2 VI ou plus (plan factoriel) | ANOVA factorielle |
| Variable dépendante binaire (ex. succès/échec) | Régression logistique, test chi-carré |
2. Le niveau de signification (valeur p)
La valeur p est la probabilité de conclure qu'un effet existe alors qu'il n'existe pas réellement un faux positif (erreur de type I). Par convention en sciences humaines :
| Seuil (alpha) | Signification | Usage |
|---|---|---|
| p < 0.05 | 5% de chance de faux positif | Standard en IHM et sciences sociales |
| p < 0.01 | 1% de chance de faux positif | Études avec enjeux plus importants |
| p < 0.001 | 0.1% de chance de faux positif | Médecine, essais cliniques |
Un seuil plus strict (p < 0.01) réduit les faux positifs mais exige un plus grand échantillon pour détecter un effet réel.
3. La puissance statistique
La puissance est la probabilité de détecter un effet qui existe réellement l'inverse d'un faux négatif (erreur de type II).
Une puissance de 0.80 signifie qu'on a 80% de chances de détecter l'effet si celui-ci est présent.
| Puissance souhaitée | Implication |
|---|---|
| 0.80 (standard) | 20% de risque de manquer un effet réel acceptable dans la plupart des études en IHM |
| 0.90 | 10% de risque nécessite un échantillon plus grand |
| 0.95 | 5% de risque réservé aux études à enjeux élevés (médical, sécurité) |
Augmenter la puissance exige plus de participants. C'est un compromis entre ressources disponibles et risque d'erreur.
4. La taille de l'effet
La taille de l'effet est une estimation de la force de la relation entre les variables indépendamment de la taille de l'échantillon.
Plus l'effet attendu est petit, plus il faut de participants pour le détecter. Différentes métriques selon le test :
| Test | Métrique | Faible | Modéré | Fort |
|---|---|---|---|---|
| t-test | d de Cohen | 0.2 | 0.5 | 0.8 |
| ANOVA | f de Cohen | 0.1 | 0.25 | 0.4 |
| Corrélation | r de Pearson | 0.1 | 0.3 | 0.5 |
| Chi-carré | w de Cohen | 0.1 | 0.3 | 0.5 |
Paramètres : alpha = 0.05, puissance = 0.80, taille d'effet modérée (d = 0.5)
| Paramètre | Valeur | Raisonnement |
|---|---|---|
| Test | t-test indépendant | 2 groupes distincts, VD continue (temps) |
| Alpha | 0.05 | Seuil standard |
| Puissance | 0.80 | Acceptable pour une étude exploratoire en IHM |
| Taille d'effet | d = 0.5 (modéré) | Différence raisonnable entre deux outils de productivité |
| N requis | ~64 participants | 32 par groupe (calculé via G*Power ou une table) |
Si on s'attend à un effet fort (d = 0.8), on n'aurait besoin que d'environ 26 participants au total. Si l'effet est faible (d = 0.2), il en faudrait plus de 400.
Expériences en ligne
Tests A/B
Un test A/B est une forme d'expérience inter-sujets menée à grande échelle sur des plateformes en ligne.
50% des visiteurs voient la variation A, 50% voient la variation B. On mesure ensuite une variable dépendante (clics, conversions, durée de session, etc.).

En termes de structure, un test A/B est un ECR à grande échelle : l'assignation aux conditions est aléatoire, il y a un groupe expérimental (B) et un groupe contrôle (A), et on mesure un effet causal.
C'est l'une des rares situations en IHM où on peut mener quelque chose qui ressemble à un essai contrôlé randomisé avec des dizaines de milliers de participants réels, dans leur contexte naturel, sans recrutement explicite.
Les tests A/B permettent de recueillir des données sur des millions d'utilisateurs réels. Mais ils comportent des limites importantes :
- Des améliorations incrémentales locales peuvent mener à une expérience globale moins satisfaisante
- On optimise facilement pour des métriques courtes-vues (clics) au détriment d'objectifs à long terme
- Il est difficile de tester des changements de design radicaux seules les petites variations sont comparables
- Les utilisateurs peuvent se comporter différemment sachant (ou devinant) qu'ils font partie d'un test
Validité de l'étude
Menaces à la validité
Une étude bien conçue doit réfléchir à deux types de validité :
Dans quelle mesure l'étude mesure-t-elle réellement ce qu'elle prétend mesurer? Concerne la qualité de la conception et de l'analyse.
Menaces : variables confondantes non contrôlées, biais de l'intervieweur, effets d'ordre, effet Hawthorne.
Dans quelle mesure les résultats peuvent-ils être généralisés à des populations, tâches et contextes plus larges?
Trois menaces principales :
- Population les participants ne sont pas représentatifs
- Contexte les tâches ou le cadre ne correspondent pas au monde réel
- Moment l'étude est trop courte, trop longue, ou mal chronométrée